
If you’ve ever wondered how search engines find your site, the answer is simple: they send out crawlers. Built to mimic how human users interact with your website, search engine crawlers review the structure of your content and bring it back to be indexed.
When you build your website to make it easier for these bots to find and parse important information, you’re not just setting your website up for higher rankings; you’re building a seamless experience for human users as well.
We covered the crawling process briefly in How Do Search Engines Work? The Guide to Understanding Search Engine Algorithms, but we’re taking it a step further here. This article is a deep dive into the underlying functionality of web crawlers—breaking down the different types of crawlers you’ll encounter, how they work, and what you can do optimize your site for them.
At the end of the day, it’s each crawler’s job to learn as much as possible about what your website has to offer. Making that process efficient ensures that you’re always presenting the most up-to-date content in the SERP.
What Is a Search Engine Crawler?
Search engine crawlers, also called bots or spiders, are the automated programs that search engines use to review your website content. Guided by complex algorithms, they systematically browse the internet to access existing webpages and discover new content. Once data has been captured from your website, web crawlers take it back to their respective search engines for indexing.
Throughout this process, crawlers look at the HTML, internal links, and structural elements of each page in your website. That information is then bundled together and formulated into a comprehensive picture of what your website has to offer.
How Do Search Engine Crawlers Work?
Search engines send out these bots on a recurring basis to crawl and recrawl your site. When a crawler reviews your site, they do so methodically, following the rules and structures defined by your robots.txt file and sitemap. These elements give the crawler instructions for which pages to look at and which pages to ignore, and they provide up-to-date information on the composition of your site.
When a crawler comes to your website, the first thing it looks at is your robots.txt file. This file breaks down the specific rules for which parts of your website should and should not be crawled. If you don’t set this up correctly, there will be issues with crawling your site, and it will be impossible to index.
The two main functions you should pay attention to in the robots.txt file are allow and disallow:
- Setting a URL to allow means that web crawlers will take them back to be indexed.
- Setting a URL to disallow means the web crawler will ignore them.
The majority of the content you create should be set to allow—only private pages, such as user accounts or team pages containing personal information, should be ignored.
Here’s a template of how to write this file:
User-agent: [the name of the web crawler]
Allow: [URL strings you want to be crawled]
Disallow: [URL strings you don’t want to be crawled]
Once you’ve designated the parts of your website that web crawlers can access, they’ll move through your content and link structure to parse the underlying framework of your website. To make that process more efficient, crawlers review your sitemap.
A sitemap is an XML file that lists every URL your website contains. It provides a structural overview of each page and guides the search engine crawler through your site as quickly and efficiently as possible. Your sitemap can also be used to assign priority to certain pages of your website, telling the crawler what content you think is most significant. In doing so, you’re telling search engines to boost the perceived ranking importance.
Think about web crawlers as cartographers or explorers with a goal of mapping every corner of a newly discovered landmass. Their expedition might look something like this:
- Crawlers start out at the search engine to prepare for their journey.
- They venture out to every corner of the internet in search of data (websites) to fill in their map.
- Using the robots.txt and sitemap files, the crawler digs through the content of your site to build a comprehensive picture of what it contains.
- Crawlers take what they’ve learned on their journey and bring it back home to the search engine.
- Then, they add any new information about your site to the search engine’s master map, which will then be used to index and rank your content according to a number of different factors.
- From there, crawlers do it all again, and again, and again, and again.
With the ever-changing landscape of websites on the internet, web crawlers have to perform each of these steps regularly to ensure that they have the most up-to-date information possible. To accomplish that, most crawlers will review your site every few seconds, ensuring that any updates you make are promptly indexed, ranked, and presented to searchers in the SERP.
As you’re building or updating your website, think about what you can do to make it as easy as possible for crawlers to fill in their map.
Top 5 Search Engine Crawlers
Every major search engine on the planet has a proprietary web crawler. While each is functionally performing the same tasks, there are subtle differences in how each crawls your site. Understanding those differences will help you build a website that’s tailored to each search engine.
Googlebot
As the most popular search engine in the world, Google’s protocols are the standard for most crawler programs. Their crawler, the eponymous Googlebot, is actually made of two separate crawler programs, one simulating a desktop user and one simulating a mobile user, named Googlebot Desktop and Googlebot Smartphone, respectively. Both bots will crawl your site approximately every few seconds.
According to Neil Patel, one of the best things you can do to optimize your site for Googlebot is to keep things simple: “Googlebot doesn’t crawl JavaScript, frames, DHTML, Flash, and Ajax content as well as good ol’ HTML.” Building your site in this manner can go a long way toward streamlining the experience for your readers as well—properly formatted HTML code renders much faster and more reliably than the other protocols.
This means that your site will run faster, which is a positive signal Google looks at when ranking your site. As a result of optimizing your site for crawlability, you’re also increasing it’s ranking potential. Keep this in mind as you’re reading through how other search engine crawlers review your site. It’s possible to tweak your website structure to appeal to each directly. Next up, Bingbot.
Bingbot
Bing’s primary web crawl is called Bingbot (you’ll see a theme here with the names). They also have crawlers called AdIdxBot and BingPreview for ads and preview pages, respectively. Unlike Google, however, Bing does not have a separate crawler for mobile sites.
While Bingbot follows many of the same standards as Google, you do have some additional control when it comes to how and when Bing crawls your site. Bing will optimize their crawl times based on proprietary algorithms but allow you to tweak those times using their Crawl Control tool.
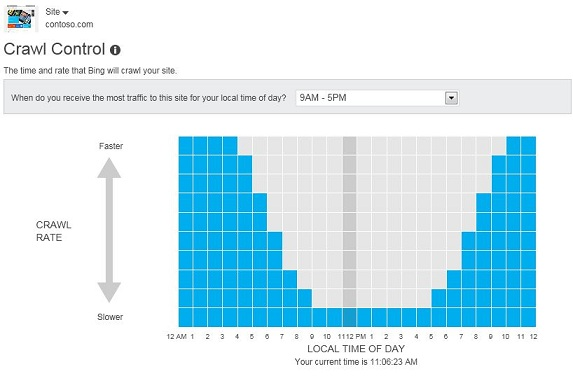
This control ensures that you won’t experience any issues with site speed at times of high incoming traffic. Bing also includes a lot of information on how they go about the process in their Webmaster Guidelines.
Learning these guidelines helps you tailor your site to their crawler, which helps you increase traffic and build a better experience for your visitors. When you understand how Bing uses their web crawler can, it also helps you understand our next search engine as well.
DuckDuckBot
DuckDuckBot is the crawler program for privacy-minded search engine DuckDuckGo. While DuckDuckGo uses Bing’s API to surface relevant search results, along with approximately 400 additional sources, their proprietary crawler still does some of the work of reviewing your website.
The main difference in their crawler is that it prioritizes the most secure websites first. While it’s a no-brainer that you should be using a secure SSL protocol for your website, for both the security and the SEO benefits, DuckDuckBot focuses on security as the most important ranking factor.
If you’re targeting rankings in DuckDuckGo, understanding how to make your website as secure as possible is the way to go. That means dropping any invasive tracking JavaScript or data-mining ad platforms. But it can be beneficial if your target audience is security/privacy-minded.
Just keep in mind that going after search rankings on a specific platform can be troublesome if you’re not careful. You don’t want to pigeonhole your site by targeting too narrowly.
Baiduspider
Baiduspider is the web crawler of Chinese search engine Baidu. While something to consider mostly when you’re going after specific international audiences, Baiduspider is one of the most frequent site crawlers on the web. They also have specific rules for how they read a robots.txt file.
When you’re creating a robots.txt file for the Baiduspider, you have the ability to index your site and, at the same time, block the following functionality:
- Following links on the page
- Caching the results page
- Reviewing images
This kind of specificity gives you more control than many of the other crawlers we’re talking about today. Baidu also tells us that they use a number of different agents for crawling specific kinds of content. This gives you the ability to create even more targeted rules based on the bot you believe is actively crawling your site.
Yandexbot
Yandexbot is the crawler for Yandex, a Russian search engine. Similar to Baidubot, they use the same crawler for all of the internet, with different agents for specific content types. On top of that, there are specific tags you can add to your site to make it easier for Yandex to index.
The most prominent of these tracking tags is Yandex.Metrica. Using this tag, you have the ability to increase the crawl speed for Yandex directly. Linking it to your Yandex Webmaster account takes this a step further, increasing the speed even more.
When you’re thinking about how to target specific crawlers with your website’s infrastructure, consider that each one is looking for more or less the same thing, with a few small tweaks to the way they go about it. Building a site that’s logical, structured according to the rules we talked about in the “How Do Search Engine Crawlers Work?” section and easy to interact with, will ensure that you have the most ranking potential from this perspective.
Optimizing Your Site for Search Engine Crawlers
Crawlers take a very systematic approach to reviewing your site. An understanding of how they go about collecting information and bringing it back to be indexed helps boost your ranking potential. Any missteps in the process can not only hurt your rankings but also make your site invisible to search engines.
The most important thing you need to do is create a standardized robots.txt file and an up-to-date sitemap. This ensures that only the proper pages of your website are crawled according to the robots.txt tile. And you’ll always be able to showcase the correct link structure and priority in your sitemap. To make this easier, you can define your sitemap directly in the robots.txt file:
User-agent: [the name of the web crawler]
Allow: [URL strings you want to be crawled]
Disallow: [URL strings you don’t want to be crawled]
Sitemap: [https://www.yourdomain.com/sitemap.xml]
Just make sure you’re using the correct URL structure, based on your website provider.
For most of the bots you’ll encounter, crawl rates will be optimized based on specific rules in the search engine algorithms. But it’s always a good idea to double-check these crawl rates when you have the chance. Bing, DuckDuckGo, and Baidu all provide tools for reviewing and updating crawl rates based on what’s best for your site. If your site receives an influx of traffic during weekday mornings, adjusting the crawl rate lets you tell the crawler to slow down during those times and crawl more in the late evening.
Using this logic, you can plan your publishing schedule to create public-facing content just before the crawlers do their thing. That way, you’ll ensure that every new page you create is crawled, indexed, and ranked as quickly as possible.
Another way to ensure this level of crawl efficiency is to make use of internal linking. When you connect similar pages together in a logical and straightforward manner, it gives crawlers an easy way to flow through the content faster. That lets them paint a more comprehensive picture of your website’s overall value.
Don’t forget external linking opportunities, either. When you’re linked to from domains with more authority or a longer tenure on the web, it gives crawlers a reason to ensure your page is as up-to-date as possible. Many of these programs will prioritize websites with higher ranking and domain strength, so the better links you’re able to garner, the more attractive your site will be.
Crawling is the first step toward getting your content to rank well in search engines. It’s important to streamline the process so any search engine crawler that hits your site can quickly parse the structure and head back home to add it to the index. From there, you’re one step closer to getting your website in the SERP.
Make Crawling Your Website Easy
When a search engine crawler reviews your site, they’re doing so in much the same way as a user. If it’s difficult to parse data correctly, you’re setting yourself up for poorer rankings. With a solid understanding of the underlying technology and protocols these crawlers follow, you’re able to optimize your site for better ranking potential from the get-go.
Optimizing the crawlability of your page is probably one of the easiest technical changes you can make on your website from an SEO perspective as well. As long as your sitemap and robots.txt file are in order, any changes you make will appear in the SERP as soon as possible.
