
If you're attempting to get your pages indexed in Google, Google Search Console can be one of the best resources for you. However, it can also become quite a headache when you run into indexation errors. In this post, we'll cover one of the most common indexation errors, and show you how to fix it.
Pages cannot be crawled or displayed due to robots.txt restriction
One of the most common errors in Google Search Console is the "pages cannot be crawled due to robots.txt restriction" error. What does this mean?
This error indicates that you've blocked Google's crawler from crawling your landing page(s).
Why does this error display?
If you're running into this error message your robots.txt file will look like this:
User-agent: *
Disallow: /
This would tell Google to stop crawling your entire site.
User-agent: *
Disallow: /example-page/
This would tell Google to stop crawling this specific path. Variations of this URL like /example-page/path would also be blocked.
Tip - The * rule applies to every bot unless there is a more specific set of rules
If you've added the Googlebot user agent your robots.txt will look like this:
User-agent: Googlebot
Disallow: /
You may still see your pages in the search results, but Google will display the wrong title and have a meta description that reads "No information is available for this page."
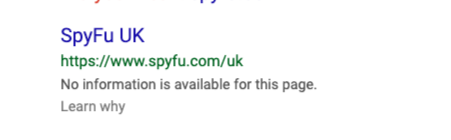
Disallowing a page(s) via Robots.txt does not drop them from the Google Index, so if you have any pages linking to your disallowed pages, they will still show in the search results.
How to solve this
Luckily, there's a simple fix for this error. All you have to do is update your robots.txt file (example.com/robots.txt) and allow Googlebot (and others) to crawl your pages.
If you only want Googlebot to crawl these pages your robots.txt file will look like this:
User-agent: Googlebot
Allow: /
If you're going to allow all user-agents to crawl your site your robots.txt will look like this:
User-agent: *
Allow: /
You can test these changes using the Robots.txt tester in Google Search Console without impacting your live robots.txt file. Once you've validated your changes, you'd carry those over to your live robots.txt file.
